As a data professional, you know how crucial it is to have a seamless data preparation process. Microsoft Fabric's Data Wrangler is here to revolutionize the way you work with data. In this post, we'll dive into the world of Data Wrangler and explore its features, benefits, and how it can accelerate your data prep workflow.
What is Data Wrangler?
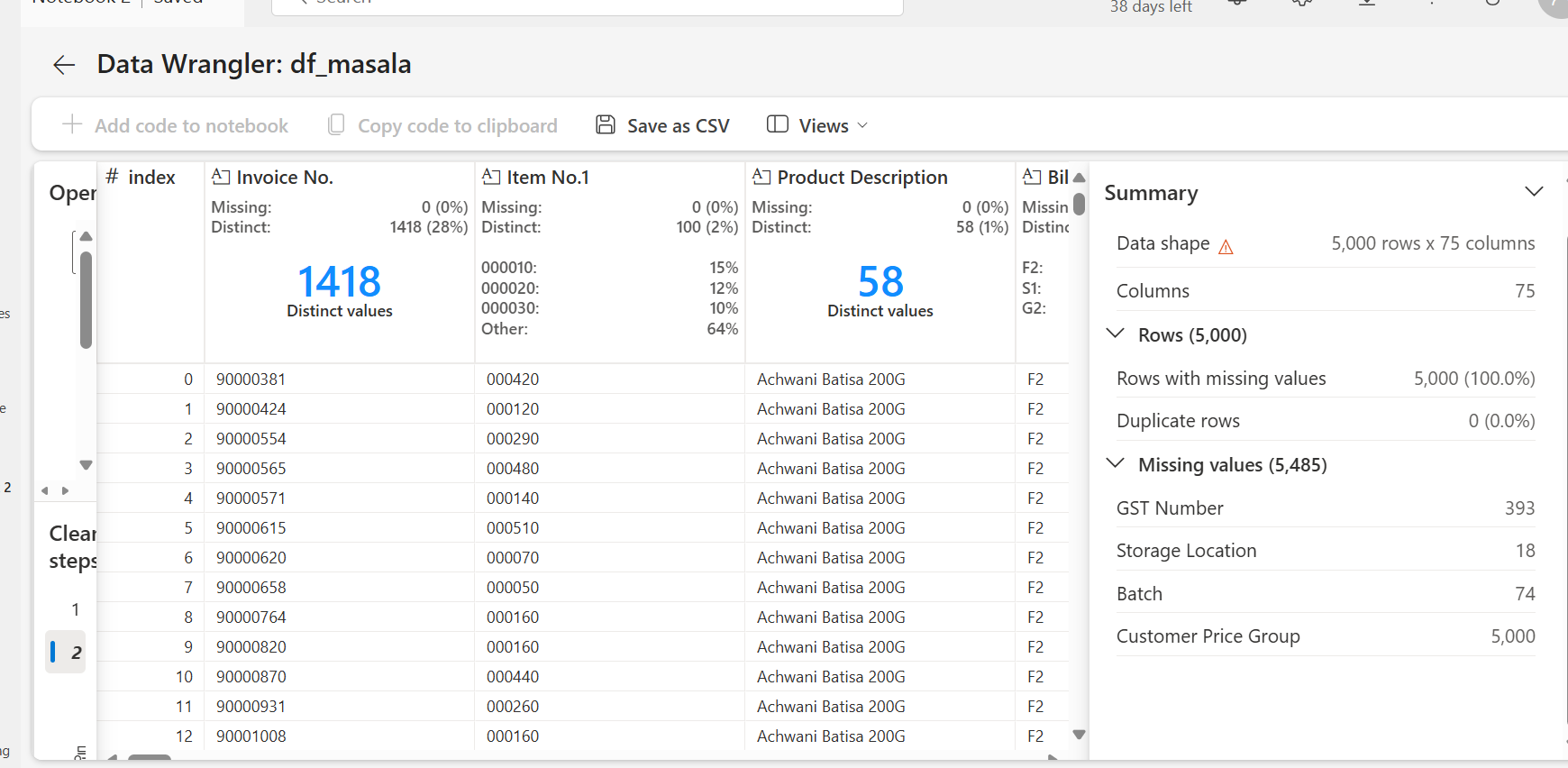
Data Wrangler is a notebook-based tool that provides an immersive interface for exploratory data analysis. It combines a grid-like data display with dynamic summary statistics, built-in visualizations, and a library of common data-cleaning operations. Each operation can be applied in a matter of clicks, updating the data display in real-time and generating code in pandas or PySpark that can be saved back to the notebook as a reusable function.
Getting Started with Data Wrangler
To get started with Data Wrangler, you'll need a Microsoft Fabric subscription or a free trial. Once you've signed in to Microsoft Fabric, switch to the Synapse Data Science experience using the experience switcher on the left side of your home page.
Launching Data Wrangler
You can launch Data Wrangler directly from a Microsoft Fabric notebook to explore and transform pandas DataFrames. Simply use the Data Wrangler dropdown prompt under the notebook ribbon "Data" tab to browse active DataFrames available for editing. Select the one you wish to open in Data Wrangler.
Choosing Custom Samples
Data Wrangler allows you to open a custom sample of any active DataFrame. You can do this by selecting "Choose custom sample" from the dropdown, which launches a pop-up with options to specify the size of the desired sample (number of rows) and the sampling method (first records, last records, or a random set).
Tips and Tricks
Data Wrangler cannot be opened while the notebook kernel is busy. An executing cell must finish its execution before Data Wrangler can be launched.
When working with Spark DataFrames, you may need to disable Arrow optimization by adding the following line to the start of your code:
spark.conf.set('spark.sql.execution.arrow.pyspark.enabled', 'false')
Benefits of Data Wrangler
Data Wrangler serves as a comprehensive tool for preprocessing data. It enables users to clean data, handle missing values, and transform features to build machine learning models. With Data Wrangler, you can accelerate your data prep workflow, reduce the time spent on data cleaning, and focus on building accurate machine learning models.
Conclusion
Data Wrangler is a game-changer for data professionals. Its intuitive interface, dynamic summary statistics, and built-in visualizations make it an essential tool for exploratory data analysis. By leveraging Data Wrangler, you can streamline your data prep workflow, reduce errors, and build more accurate machine learning models. Try Data Wrangler today and experience the power of accelerated data prep!